

DeepSeek: ladrón que roba a ladrón
y si es Chino, ¿tiene 100 años de perdón?

Muy buenos días. Escribo este newsletter el domingo bien temprano, mientras las noticias emergen como un vertedero fuera de control. A esto se suma que venimos de una seguidilla de novedades relacionadas con cómo las empresas más ricas del mundo moldean lo que pasa en internet. Los discursos, las noticias y la desinformación.
Creo que es la razón principal por la cuál DeepSeek fue “la” noticia de la semana: una empresa china ofrece una herramienta de IA de código abierto con “las mismas capacidades que ChatGPT” a menor costo y en menos tiempo. Y para colmo, fue un desarrollo orientado a la investigación y no al lucro.
¡Es nuestra Robin Hood! 🥳
Pero no tenemos ni la capacidad analítica ni los medios para saber si todo esto es tan así, aunque nos gustó mucho, ¿una historia de resiliencia quizás?
Todo esto me hizo acordar a cómo surgió cada gastronomía en el mundo: los mejores platos se desarrollaron en base a la escasés, ingenio y hambre. Pienso en el Kimchi y la cultura coreana, este alimento fermentado que fue declarado patrimonio inmaterial por la UNESCO y hasta tiene un día en Argentina. El Kimchi surgió en Corea como forma de supervivencia para conservar verduras durante los inviernos hace más de 2.000 años. Es un plato que dio lugar a una gran discusión sobre diplomacia culinaria y soberanía alimentaria.
Les dejo este hermoso documental presentado por el Centro Cultural Coreano en Argentina en el marco de Taste Of Korea 2021 sobre cómo prepara el Gimjang Kimchi para enfrentar la escasez del invierno y qué significa.
📍 El domingo que viene no habrá newsletter porque me tomo una semana de descanso ☀️. Nos encontramos nuevamente el 16 de Febrero.
📍 Este es un boletín gratuito y dominical hecho a pulmón humano. Durante Enero ofrecí a los suscriptores pagos un curso de IA como agradecimiento por el apoyo. Es atemporal, pueden consultar las clases aquí. A partir de ahora, enviaré una edición mensual de actualización.
🕣 Esta edición tiene 2200 palabras y lleva 11 minutos de lectura
1. Ladrón que roba a ladrón
David Sacks, conocido como el Zar de la inteligencia artificial, dice que DeepSeek utilizó los modelos de IA de OpenAI para entrenar a R1, un proceso que viola los términos de servicio de OpenAI y equivale a un robo.
Sabemos que OpenAI está demandado por haber entrenado sus modelos de lenguajes con material protegido por derecho de autor, lo que también equivale a un robo.
Lo cierto es que DeepSeek no informó cómo se entrenó. No sabemos qué datos deglutió. Por esa razón, los muchachos de Hugging Face lanzaron su propio modelo llamado Open-R1, una especie de duplicado de DeepkSeek pero de código abierto real. Es decir, todos los datos y componentes, incluidos los datos utilizados para entrenarlo.
El tema con DeepSeek es que no es de código abierto propiamente dicho. No detalla ni su código ni instrucciones de entrenamiento. Es una caja negra, llena de sesgos que evitan responder al 85% de las preguntas sobre "temas sensibles" relacionados con China.
Por ejemplo, al no saber demasiado sobre sus componentes, la marina de EE.UU. que prohibió el uso de DeepSeek, citando "preocupaciones éticas y de seguridad".
Claro: ¿Cuáles serán las medidas de seguridad que tome esta empresa? No sabemos nada. Venimos de intentar aprender chino porque se cierra TikTok, nos emocionamos con una IA gasolera pero no todo es color de rosa. El que si adelantó algo sobre este tema es Juan Brodersen en su boletín, en que que cuenta que este nuevo chatbot es más vulnerable, es simple engañarlo para escribir malware, fabricar contenido sensible y hasta desarrollar ransomware.
DeepSeek empezó a generar incomodidades en Europa. Italia presentó una queja por cómo usa los datos DeepSeek con respecto a las leyes GDPR, ya que considera que “los datos de muchos están en riesgo” y que no hay detalles de como la app protege a los menores de 18 que usan el servicio. Es un tema, porque esta aplicación está sugerida para mayores de 18 años pero permite a los adolescentes de entre 14 y 18 usarla leyendo la política de privacidad con un adulto.
2. El momento Sputnik de la IA
Más allá de todo lo comentado, DeepSeek marca una fecha clave en el calendario de la industria tecnológica. Un gran titular del referente de tecnología Marc Andreessen, creador del navegador Mosaic, ilustró lo que está pasando con esto: "Deepseek R1 es uno de los avances más sorprendentes e impresionantes que he visto jamás y, como código abierto, un gran regalo para el mundo" afirmó en su cuenta de X.
El logro de esta IA china con su modelo R1 es que es mucho más barato que el resto pero con las mismas capacidades que sus hermanos mayores. Es gratuito, funciona con chips de menor costo y requiere menos datos. Además, usa entre 10 y 40 veces menos energía que una tecnología de inteligencia artificial estadounidense similar.
La fecha clave es el día del lanzamiento del modelo R1: 20 de enero. En ese momento, las acciones de Nvidia se desplomaron en un 17%. Pero amigos, ¿Saben cuánto ganó Nvidia en todos estos años? Los balances para ver cómo repuntó, aún no están disponibles, pero al otro día subió un 8%.
Lo que más le dolió a OpenAI es que escaló al podio de las apps más descargadas en solo unos días. Cosas que nunca sus competidores habían logrado.
¿Qué hace?
A lo largo de estos días leí cosas que eran erróneas. Por ejemplo, que DeepSeek navega en tiempo real, como Perplexity, y no es así: llega hasta Octubre de 2023. Su opción de “búsqueda” también tiene ese tope.

¿Cómo funciona?
Su sistema usa técnicas como aprendizaje de refuerzo puro. El asistente de IA se basa en un sistema de “mezcla de expertos” para dividir su modelo en numerosos submodelos pequeños o expertos especializados en un tipo específico de datos o tareas. Al ser de código abierto, cualquier persona puede analizar, modificar o desarrollar el modelo, disponible en Hugging Face. Como comenté anteriormente, no todo. Los expertos en tecnología dicen que esto es, básicamente, un cambio de paradigma. En vez de intentar crear modelos cada vez más grandes, las empresas ahora se centran en capacidades avanzadas como las que hace DeepSeek: matemáticas, codificación y razonamiento complejo.
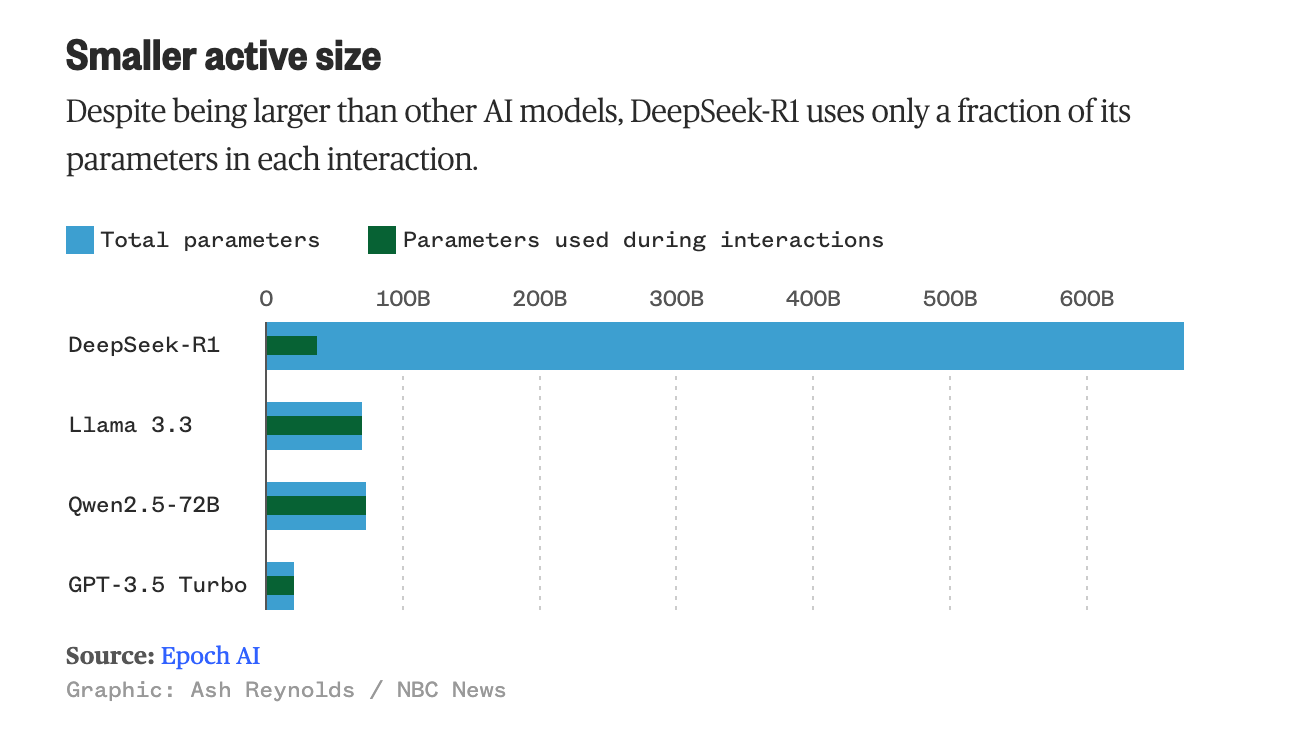
¿Por qué es más eficiente?
Porque si bien su arquitectura tiene muchos parámetros (671 mil millones) solo usa 37.000 millones durante el funcionamiento, haciendo gala de su gran eficiencia computacional. Es decir, trabaja sobre un modelo destilado, como se llama a los más pequeños y eficientes.
¿Por qué es más económico?
Tiene que ver con los precios de inferencia que es el costo que se paga por la devolución que hace el sistema de IA al pedido del usuario. DeepSeek cobra una pequeña fracción de lo que cuesta OpenAI-o1 por el uso de la API. Esta drástica reducción de los costos podría democratizar el acceso a capacidades avanzadas de IA, lo que permitiría a organizaciones más pequeñas e investigadores individuales aprovechar herramientas de IA potentes que antes estaban fuera de su alcance.
¿De quién es?
Es un desarrollo de una startup llamada DeepSeek, ubicada en Hangzhou, China. Fue creada en 2023 por Liang Wenfeng, uno de los principales inversores en metodologías Quants de China, a través del fondo High-Flyer que financia diferentes investigaciones de IA. A este muchacho lo llaman el “Sam Altman Chino”, aunque no busca dinero sino el respeto de la industria. La compañía es conocida en China por captar a jóvenes investigadores de IA en las mejores universidades y es lo que hizo High-Flyer, una firma china de comercio bursátil que financio DeepSeek.
¿Cuánto salió?
La empresa informa que gastó menos de 6 millones de dólares para desarrollar y entrenar R1 (OpenAI invirtió 100 millones de dólares para entrenar a ChatGPT), pero esta información proviene de solo artículo publicado por ellos mismos. Es decir: no hay certeza de que sea así. DeepSeek utilizó solo 2000 chips NVIDIA AI menos avanzados porque, al estar bloqueada comercialmente, es lo que pudieron adquirir en 2021.
¿Cómo empezó y cómo sigue?
Hace años que DeepSeek viene publicando modelos lingüísticos de gran tamaño, tipo ChatGPT y Gemini. El 10 de enero de 2025 lanzó su primera aplicación gratuita de chatbot, basada en un el modelo DeepSeek-V3. Tan solo 10 días después, el 20 de enero, presento su modelo de razonamiento, R1. Este es el que “hizo temblar” al mercado y que, supuestamente, está a los niveles del modelo de OpenAI o3, que todavía no fue lanzado al público, entonces, no se puede saber mucho más.
El periodista Ricardo Sametband puso a prueba la ideología de la plataforma. Es decir, qué responde cuando le preguntamos sobre asuntos fundamentales como la democracia en diferentes países. En este caso, falló. Según ilustra en esta nota de La Nación, mientras que la plataforma china define a Taiwán como una “parte inalienable de China”, para el resto de las plataformas Taiwan es una “democracia consolidada”. El resto de las respuestas relacionadas sobre censura y covid, van en esa línea, son totalmente sesgadas o “acomodadas” a un discurso lejano a la realidad.
Bien, sabemos que para proporcionar información, DeepSeek no es fiable.
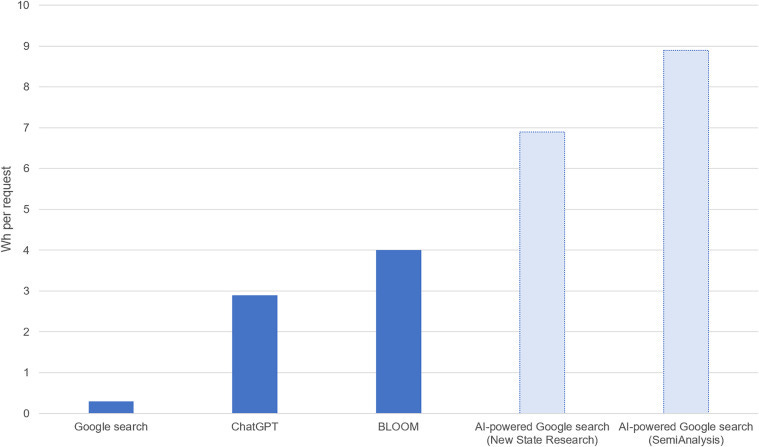
3. Pero pará: ¿cuánta energía gasta la IA?
En líneas generales, los centros de datos consumen entre el 1 y el 2% de la electricidad mundial. Si se incluyen las criptomonedas, la cifra es de alrededor del 2%. Claro que esto es algo difícil de calcular, pero un buen parámetro es que una búsqueda en chabot de IA, por ejemplo, consume aproximadamente diez veces más energía que una búsqueda estándar en Google. Si cada búsqueda en Google se convirtiera en una búsqueda de IA, la demanda anual de electricidad aumentaría de 18 a 29 TWh.
El Departamento de Energía de EE.UU. publicó en diciembre un informe con previsiones tremendas: la cantidad de electricidad que necesitarán será de como mínimo 325 teravatios hora (TWh) más de la que consumen en un año países enteros como España (246 TWh), Reino Unido (287 TWh) o Italia (298 TWh).
Según este informe, EE.UU. necesitará una potencia instalada de entre 74 y 132 GW para alimentar la infraestructura necesaria para la digitalización y la IA en 2028. Más de la que genera un país entero como España (125,6 GW a 2023), indica esta nota de El País.
No sólo energía, sino también agua. Durante 2023 los centros de datos de EE.UU. usaron 66.000 millones de litros de agua para los sistemas de refrigeración (agua evaporada) y sin tener en cuenta el agua usada para generar la energía. Esta cifra ascendería, en 2028, a 124.000 millones de litros.
La solución a esta enorme cantidad de recursos sería la energía nuclear avanzada y muchos centros de datos. España, por ejemplo, se está convirtiendo en un polo de atracción de centros de datos con desarrollos de grandes empresas como Microsoft, Amazon o Meta.
En el mundo hay tres centros mundiales de Inteligencia Artificial. Uno en China, otro en Europa y otro en Estados Unidos. El presidente de Argentina, Javier Milei, quiere que este país sea el cuarto.
Argentina cuenta con aproximadamente 14 centros de datos operando en el territorio de un país tiene una capacidad de generación eléctrica de 42.8 GW (gigavatios) en 2023 y que aún no puede soportar veranos sin grandes cortes de luz. El año pasado, Milei anunció que la nación se encuentra en una posición estratégica para convertirse en un hub de inteligencia artificial (IA). El anuncio, que se realizaría en Marzo, contempla la creación de cinco o seis centros de Inteligencia Artificial alimentados con energía nuclear.
Un dato no menor es que también el lunes 20 de Enero, además de Nvidia, se desplomaron las acciones de las compañías estadounidenses de energía, servicios públicos y gas natural a causa de que DeepSeek puso en duda el aumento proyectado en la demanda de electricidad y el gasto en tecnología en ese país.
La plataforma de correo Meco ahora ofrece un resumen de audio personalizado diario de 5 a 10 minutos de los boletines favoritos, una buena idea para escuchar las noticias diarias. Es gratuito.
Recomendados ✍️
Talk Text: Esta app de dictado mejora nuestro discurso y lo escribe mientras le dictamos, borra los ehhh, y las palabras evitables. Permite practicar y mejorar discursos, ponencias o cualquier tipo de charla. También genera o regenera textos según las necesidades. Se puede probar gratis.
El mejor infarto de mi vida: La serie de Netflix que recrea el cuento de Hernán Casciari y que está basado en una historia real, me encantó. La vi habiendo leído una crítica que decía que era malísima y, afortunadamente, fue una gran sorpresa. Seis capítulos de 30 minutos que, además, te dejan un mensaje esperanza en las personas y las casualidades (que no existen).
Bookshop.org: La librería online que apoya al mercado de la literatura independiente acaba de lanzar su tienda online para que los lectores puedan evitar a Amazon pues monopolio o bien, comprar allí y apoyar a sus autores favoritos. Por más que nos quede algo lejos, vale la pena visitar esta nueva propuesta alternativa.

Este news es semanal y gratuito pero hay diferentes maneras de contribuir con el trabajo independiente:
Si querés auspiciar LadoBnews, contactame.
Podés colaborar de diferentes maneras aquí.
Para el curso de IA, más info aquí.
Por charlas, consultorías o talleres, podés contactarme aquí.
***Cualquier error tipográfico es intencional. Podés darme feedback en privado. Si es en público: se amable***