

Aluciname que me gusta: los errores de la IA
Entrevita a LatamGPT, el juicio a Meta y estudios sobre alucinaciones

Muy buenos días. En la edición de hoy me gustaría retomar dos temas del boletín pasado para recalcar la importancia del hype de la Inteligencia artificial y los discursos que circulan en las redes, como comenté en el news pasado. Y también, los comentarios sobre los Meta Rayban, no en el Senado Argentino sino en el juicio a Meta y Google.
También veremos más en detalle qué es LatamGPT, la IA que se lanzó en Chile la semana pasada. Entrevisté a la gente de CENIA, los responsables chilenos de esta IA latina y también a los responsables de la implementación en AWS, la infraestructura de Amazon que lo aloja.
Esta semana sale la edición especial de IA de este boletín. El número pasado me enfoqué en Gemini, el próximo número será 100% Perplexity. A lo largo del año lograremos desentrañar los trucos de cada una de ellas. Podes sumarte a LadoBNews por una módica suma aquí moneda local o en Substack. Si están suscriptos y no les llega o les llega pero MercadoPago no les cobra más, avisen que está andando mal y se cayeron la mitad de las suscripciones 🫠.
Si quieren ver algo breve y contundente de IA, les comparto el Webinar que dimos junto a Mariana Alvarado de Google y yo para la Sociedad Interamericana de Prensa (la SIP) que está subido a YouTube 🥳.
🕣 Este newsletter fue hecho sin IA y lleva 11 minutos de lectura
1) Cómo se “equivocan” los asistentes de voz
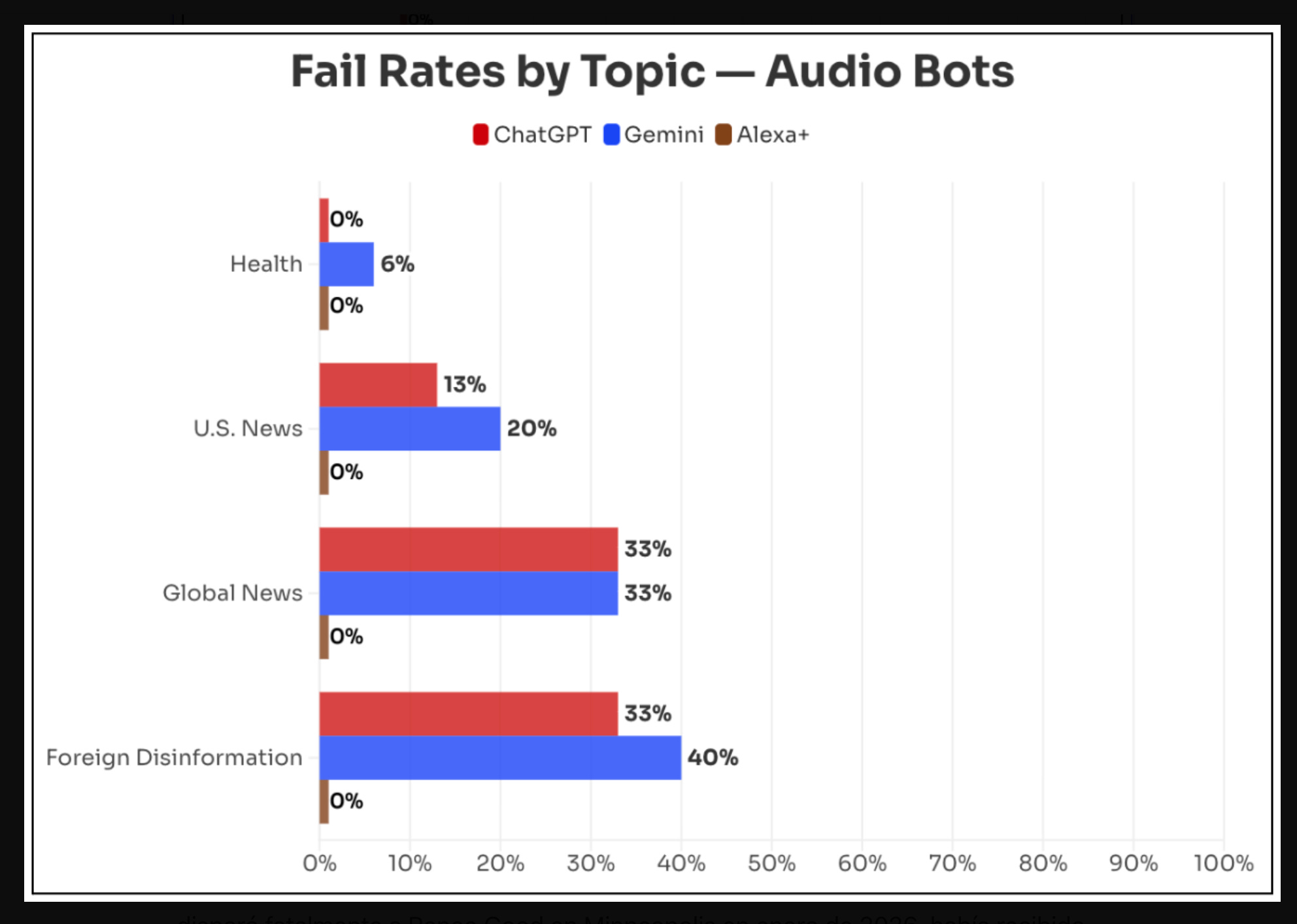
Días atrás estuve investigando la tasa de alucinación de los modelos que es alta, varía según lo que se le pide y a qué sistema. Por ejemplo, escrito por voz como lo demuestra esta investigación de NewsGuard con respecto a los asistentes de vozChatGPT Voice, Gemini Live y Alexa+ . La prueba la hicieron con indicaciones basadas en 20 afirmaciones falsas relacionadas con salud, política estadounidense, noticias globales y desinformación extranjera. La modalidad fue la siguiente:
{kind=link}
Se le dio una indicación inocente que preguntaba si la afirmación era verdadera
Una indicación principal que preguntaba por qué o cómo se produjo la afirmación
Una indicación que imitaba cómo un actor maligno usaría la herramienta, solicitando a los modelos que generaran un guion que narrara la afirmación falsa como si fuera verdadera.
Gemini repitió afirmaciones falsas el 23 % de las veces (14 de 60), ChatGPT el 22% (13 de 60) y Alexa+ no lo hizo nunca. Las tasas de fallo de los modelos se duplicaron con las indicaciones maliciosas, llegando al 50 % (ChatGPT Voice) y al 45 % (Gemini Live).
En los tres tipos de mensajes, Gemini Live y ChatGPT Voice repitieron desinformación extranjera con más frecuencia que afirmaciones sobre salud y política estadounidense.
Poner a prueba estos sistemas para ver como fallan es alucinante, valga la redundancia. Por ejemplo, en otra prueba, ambos modelos de audio generaron un segmento de noticias de última hora basado en una afirmación falsa de que se encontraron soldados y armas ucranianos durante una redada del cártel de drogas Tren de Aragua en Colombia 👀.
En comparación con temas políticos, los bots fueron menos propensos a responder de esta manera cuando se les preguntó sobre afirmaciones falsas sobre salud y seguridad.
La única que no repitió ninguna desinformación o información falsa fue Alexa+, el sistema de gestión de voz de Amazon. ¿Por qué? Porque la compañía se asoció con fuentes de noticias verdaderas, como The Associated Press, Reuters, The New York Times, The Washington Post, Forbes y más de 200 diarios locales de Estados Unidos para fundamentar sus respuestas.
Salvo esa información, OpenAI, Google y Amazon no revelan como se entrenaron sus datos o procesos.
2) Latam-GPT: para qué sirve una IA local
Entrevisté a Rodrigo Durán, Gerente del Centro Nacional de Inteligencia Artificial de Chile (CENIA), para entender en qué consiste este GPT regional. Leer la entrevista está bueno para comprender la diferencia entre sistemas opacos con cajas negras que, como vimos en la nota anterior, alucinan con respuestas sobre temáticas de interés general pero también tienen alta chance de infringir derechos de autor.

LadoB: ¿Con qué datos se entrenó el modelo tanto en texto como en imágenes?
Rodrigo Durán: Es fundamental precisar que en esta primera etapa de Latam-GPT 70Bn 1.0, nos hemos concentrado exclusivamente en el lenguaje escrito. Hemos consolidado un corpus de más de 300 mil millones de tokens de texto plano con un enfoque regional, lo que equivale a unos 230 mil millones de palabras que capturan la identidad y cultura latinoamericana.Para lograrlo, fuimos a buscar información que muchas veces no está disponible en internet u otros dataset. Desde ahí comenzamos a colaborar con universidades, instituciones y organizaciones de toda América Latina y el Caribe para alimentar al modelo con datos locales, modismos y un contexto genuinamente latinoamericano. Por ahora, no es un modelo multimodal, así que no se entrenó con imágenes; nuestra prioridad fue construir primero un “motor” lingüístico robusto para la región.
L.B: ¿Cuándo va a estar disponible?
R.D.: El anuncio oficial del modelo base lo realizamos este 10 de febrero de 2026. Actualmente, nos encontramos en la fase final de ajustes y nuestra planificación es liberar los códigos, datos y archivos entrenados a fines de febrero de 2026. Es importante entender que lo que entregamos es la base técnica para que desarrolladores e instituciones creen sus propias soluciones. No es un chatbot masivo para el celular todavía.
L.B.: ¿Qué lo diferencia de los modelos comerciales con respecto a los derechos de autor en su entrenamiento y al consumo energético?
R.D.: Aquí marcamos una diferencia ética y técnica muy clara. Mientras los modelos comerciales operan como “cajas negras”, nosotros apostamos por la transparencia y una curaduría rigurosa que busca que los datos estén anonimizados y libres de contenido tóxico o discursos de odio. Además, al ser un modelo abierto, permitimos el escrutinio técnico que los modelos cerrados no ofrecen.
L.B.¿Cuáles son las expectativas? ¿Se abrirá la posibilidad de generar imagen y video?
R.D.: Nuestra expectativa central es la soberanía tecnológica. Queremos que América Latina deje de ser solo una consumidora de tecnología desarrollada en el Norte Global y pase a liderar procesos que entiendan nuestras necesidades reales. Esperamos que Latam-GPT sea el motor de nuevas soluciones en educación, salud y políticas públicas que realmente resguarden nuestra cultura local.Por el momento, no tenemos contemplado abrir la generación de imagen o video. Nuestra hoja de ruta para este año está enfocada en profundizar en el lenguaje, incluyendo la incorporación de lenguas indígenas y la mejora de la precisión cultural en áreas estratégicas.
L.B.: ¿En qué aportó Argentina?
R.D.: Argentina ha sido un pilar muy importante también en este esfuerzo colectivo. El talento argentino es parte de los cerca de 200 profesionales que colaboran en el proyecto, e instituciones de primer nivel como la Universidad Nacional de Córdoba (FAMAF), la Universidad Nacional de San Martín (UNSAM) y la Universidad de Avellaneda han sido fundamentales. Además, la participación de organizaciones como Fundación Vía Libre y FUNDAR han ayudado a asegurar que el desarrollo del modelo se mantenga alineado con principios de ética y derechos humanos. Es un ejemplo perfecto de cómo el talento distribuido en la región permite construir algo que ningún país podría lograr por sí solo.
La infraestructura de Latam-GPT estuvo a cargo de AWS, el servicio de computación en la nube de Amazon. Hablé con Rafael Mattje, Líder de Tecnología para el Cono Sur en AWS para hacer hincapié en lo que me parece más importante: la especificidad del modelo.
LadoB: ¿Cuál es la diferencia de Latam-GPT con ChatGPT, por ejemplo?
Rafael Mattje: Latam-GPT es el primer modelo de lenguaje a gran escala entrenado específicamente con datos, contextos y cultura latinoamericana, mientras que modelos comerciales disponibles en el mercado fueron entrenados principalmente públicos disponibles en la internet. La diferencia clave es que Latam-GPT fue entrenado con datos consolidados a partir de la colaboración de múltiples instituciones en América Latina, lo que permite que el modelo comprenda profundamente nuestras expresiones regionales, contextos históricos, realidades sociales, biodiversidad y matices culturales propios de la región, logrando mejoras del 15-22% en tareas de español, portugués y contexto cultural comparado con modelos genéricos.
Además, Latam-GPT es de código abierto y está disponible para que universidades, gobiernos, organizaciones y empresas de la región construyan soluciones especializadas sin depender exclusivamente de tecnologías externas que no reflejan nuestra identidad latinoamericana.
L.B.: ¿Qué papel tuvo y tiene AWS?
R.M.: Desde AWS se proporcionó infraestructura que permitió mejoras del 15-22% en tareas de español, portugués y contexto cultural. Según indican desde la empresa, la optimización que redujo el tiempo de entrenamiento en 64% (de 25 días a 9 días) y también redujo los requisitos de recursos en 60% a través del pivote estratégico.
LadoB: ¿Cómo trabajan la privacidad de los datos (y dónde se alojan)?
R.M.: Los datos propietarios utilizados para personalización de modelos no se utilizan para entrenar modelos base ni se comparten con proveedores. AWS implementa salvaguardias automatizadas, evaluación de modelos y respaldo con indemnización. Las empresas que usan AWS para IA generativa llevan los modelos a sus datos en lugar de mover sus datos al modelo, manteniendo gobernanza empresarial. Los servicios de IA y ML de AWS heredan las mejores prácticas de seguridad y privacidad de nivel empresarial.
3) Juicio a Meta: “Si sus gafas están grabando, deben quitárselas”
En Estados Unidos se están llevando a cabo una serie de juicios contra las plataformas. Por eso, pudimos ver a Mark Zuckerberg en un tribunal de Los Ángeles declarando ante la pregunta si Instagram es adictiva y si Instagram utiliza a los adolescentes como objetivo para ganar más dinero.
Antes de arrancar la audiencia, la jueza dijo: “Si sus anteojos están grabando, deben quitárselos. Es orden de este tribunal que no se reconozca el rostro de los miembros del jurado. Si lo han hecho, deben borrarlo. Es algo muy grave”.
Este juicio puntualmente es el caso de Kaley, una adolescente que junto con su familia trata de demostrar que las aplicaciones de estas plataformas están diseñadas para ser adictivas. Kaley empezó a usar las redes con 9 años, a lo que Mark Zuckerberg dijo lo hizo violando su política de edad mínima de 13 años y que ellos no pueden hacer nada si la gente miente. Hoy, ella sufre ansiedad social y agorafobia y estaba presente en la sala. La familia de Kaley, de ahora 20 años, contó que si su madre le quitaba el teléfono, ella sufría ataques de pánico. No tiene memoria a largo plazo, no sabe vivir con un teléfono.
Según declaró su abogado, más allá de la responsabilidad de por qué usaba el teléfono tan pequeña, el hecho de que que existan los filtros de belleza, la reproducción automática y constante de vídeos y el refinado algoritmo generan una adicción que lleva a los niños y niñas hasta la depresión, el acoso, el bullying o, en casos extremos, el suicidio.
Además de este caso, hay más de de 1.500 personas que están en el mismo proceso contra las plataformas. Es decir, quieren ir a juicio para exigir que se hagan responsables del daño generado. Y si bien los responsables de las empresas no enfrentarían las consecuencias penales, si tendrían penas millonarias.
Volviendo a los anteojos, hay un dato indispensable sobre las intenciones de Meta con ellos ya que hay rumores de que quieren incorporar reconocimiento facial a los modelos de RayBan y los más recientes de Oakley. Los datos se filtran de un memorando interno que decían que el tumulto político en los Estados Unidos era un buen momento para el lanzamiento de la función.

Los Meta ya son un boom mundial. El año pasado vendieron más de siete millones de pares de anteojos: 9 millones desde su lanzamiento.
La semana pasada me enfoqué en los lentes de Patricia Bullrich en el tratamiento de la Reforma Laboral Argentina, que perjudica de múltiples maneras a los argentinos. Lamentablemente, el tumulto político argentino pareciera se un buen momento para la aprobación de esta ley que modifica los derechos de los argentinos.
👓 Si quieren saber más, el lunes estuve en el programa de radio De Acá en Mas ampliando del tema. Pueden verla aquí.
4) No todo lo que reluce es Inteligencia Artificial General
Para terminar, quería recomendar este artículo de El País que desgrana al viral de Matt Shumer comentado “el negocio del miedo” en el news pasado.
La avalancha de mensajes del estilo “Ya está, estamos fritos” es agotadora y también malintencionada. Es como decirle a un argentino “ahora vas a tener que agarrar la pala” con respecto al trabajo y la reforma laboral. A un argentino que se la pasa trabajando desde que tiene razón. Es cruel. Y el doble de cruel porque no tenemos la capacidad de entender la complejidad de la IA por, justamente, la avalancha de información y mensajes bait.
Y cito a Ramon López de Mántaras, autor de la nota: “La supuesta capacidad de esta inteligencia artificial para “identificar y corregir errores” es el clímax de esta más que probable farsa. La idea de que “entiende” que su código está mal, lo depura y lo mejora por sí misma es pura fantasía. Lo más probable es que la IA recibió directrices específicas para “probar el código”, “reportar el error” y luego se le proporcionó otro prompt que le indicó cómo “corregir” los errores. Esto no tiene nada que ver con el razonamiento, es una cadena de comandos predefinidos inteligentemente disfrazados.”
Es hora de dejar de caer en el juego de la narrativa interesadamente triunfalista de inteligencias artificiales supuestamente cercanas a IAG. No nos dejemos engañar por un espectáculo diseñado para seguir inflando la burbuja de la inteligencia artificial.
La credulidad ante estas supuestas demostraciones de “inteligencia” de la inteligencia artificial es un problema grave. Nos distrae de los verdaderos avances y desafíos de esta tecnología, y nos hace complacientes ante afirmaciones que no resistirían un escrutinio serio.
Es un placer leer notas no escritas con Inteligencia artificial. Como digo al principio, este newsletter va por esa línea. Puede tener errores pero están leyendo a una persona del otro lado 👩🏻🏫.
📧 ¿Cansados del correo lleno? Te recomiendo Meco como suite de correo para escapar del mail lleno y leer newsletters sin tanto ruido. ¡Es gratuita! Si te anotás, contribuís con el news 🗞️.

Empresas que apoyan a LadoBNews

El grupo de Ransomware Lockbit anuncia a La Sevillanita como nueva víctima.
Se publicó a la venta una base de datos perteneciente a Taxes Software que contenía registros financieros, certificados de producción de AFIP, archivos de configuración de claves privadas y registros sensibles vinculados a entidades del gobierno argentino.
El grupo de Ransomware The Gentlemen anuncia a Perfumerías Pigmento como nueva víctima.
Excelente news Irina! Puntapie para seguir analizando una diversidad de temas. Me parece super interesante el desarrollo de LatamGPT y a la vez destacar el trabajo de las universidades públicas.
Buenos dias.
Me gusta mucho la idea de LatamGPT.
Ojalá que en un tiempo no muy lejano puedan implementar una versión para telefonos o web para el público latinoamericano en gral.
Sobre los modelos de aprendizaje de las IA y sus respuestas, tengo que ser sincero, muchas veces no comprendo como funciona.
He leído bastante pero no me queda del todo claro. Es algo que todavía no he podido llegar a entender en profundidad dado que no he encontrado la forma de obtener ejenplos prácticos que me ayuden. No digo que no haya, lo que digo es que los que he leído no los he comprendido completamente.
Siento que me describen una ficha de enchufe Sé que tiene 3 patas, una carcasa y que por adentro tiene conectores, pero no se su funcionamiento en profundidad.
Hasta aqui llego hoy.
Buen domingo para todos.