

El archivo de Anna: la pesadilla para los derechos de autor
Entrevista a Tweety González y Mauro Eldritch sobre sus consecuencias

¡Muy buenos días! Hubo tantas novedades que no entrarían en un solo boletín. Por eso haré un poco de autobombo ya que las estuve cubriendo de invitada en algunos programas y en mi Instagram.
Estuve en TN hablando de Grok y la función de desnudar con IA a las personas. Y en El Destape hablando largo y tendido con Noe Barral Grigera sobre trabajo, inteligencia artificial, desinformación y el apagón de Irán. Dos deepfakes se transformaron en desinformación: El falso venezolano preso y el falso bombero Carlos Martinez.
Aproveché mucho los días sin news para ponerme al día porque la IA no perdona y lleva tiempo actualizarse. Mi misión, intentar explicarlo fácil en estas dos propuestas.
👩🏻🏫 ¡Nueva MasterClass! Se viene una nueva clase en vivo (por Zoom) de IA el 10 de Febrero de 18 a 20 horas. Hay precios promocionales hasta el 20 de enero (y si vienen de a dos, también). Si te interesa participar, inscribite aquí.
📝 Este viernes sale el curso de IA 2026 para suscriptores pagos de LadoBNews. Podes sumarte por una suma módica aquí.
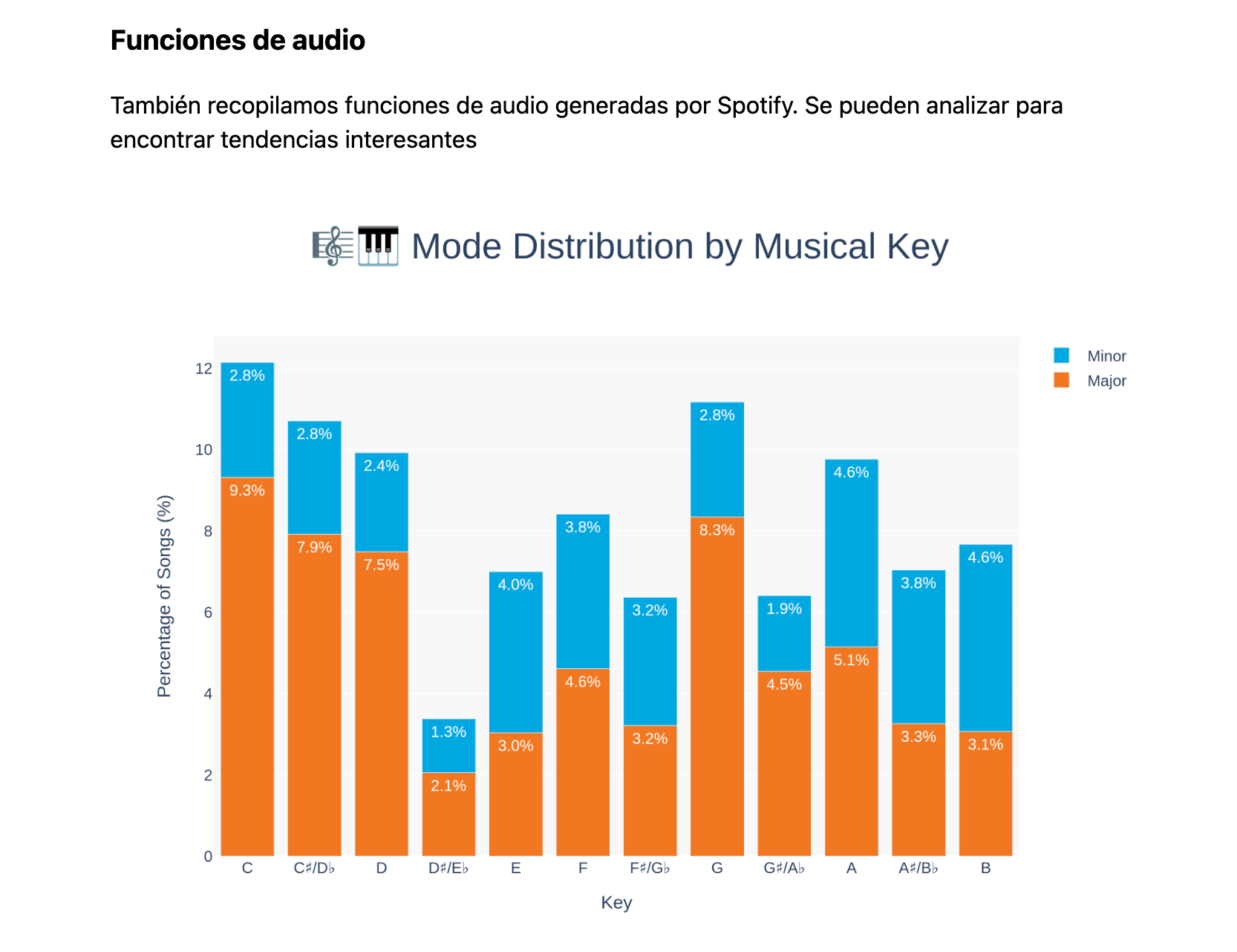
El tema que nos compete hoy viene de este boletín anterior y tiene que ver con la cultura libre, la piratería, las corporaciones de tecnología y la Inteligencia Artificial. Esta semana, además, Bandcamp anunció que no permitirá la publicación de música creada total o parcialmente con IA, en contraste con Spotify, donde en los últimos meses se multiplicó la música generada con inteligencia artificial.
En el news de hoy:
Anna’s Archive: la pesadilla de los derechos de autor
Tweety González: ¿que tan bien protegido tienen el contenido?
Mauro Eldritch: “mucho material logró conservarse así”
🕣 Este boletín lleva 9 minutos de lectura. Gracias por acompañar 💪
1) Anna’s Archive: la pesadilla de los derechos de autor
El 20 de diciembre de 2025 Anna’s Archive “raspó” la música y los metadatos de Spotify con el objetivo de preservar la música en línea. El grupo anunció una extracción de datos sin precedentes de casi 300 terabytes que también contienen metadatos de 256 millones de pistas y archivos de audio de Spotify para 86 millones de piezas musicales: esto es un 99,6 % de las escuchas en la plataforma.
Anna’s Archive es un motor de búsqueda de código abierto que nació en noviembre de 2022 después del cierre de Z-Library. Se presenta como un metabuscador open source que tiene el objetivo de preservar el conocimiento humano de forma descentralizada. Este sitio, que va cambiando de dirección constantemente, permite a los usuarios acceder a contenido pirateado, de pago o protegido con muro de pago. Es decir, un libro, un disco, una película.
Como sabrán quienes usan Spotify, la música no se puede descargar en los dispositivos, sino escuchar o guardar una copia temporal. Para proteger ese contenido, Spotify utiliza DRM (Digital Rights Management), que es un conjunto de tecnologías diseñadas para evitar copias y redistribución no autorizada.
Y es un tira y afloje con las editoriales o productoras. El mes pasado, Google eliminó más de 749 millones de enlaces de resultados de búsqueda que dirigían a Anna’s Archive en base a 784 millones de solicitudes de eliminación de enlaces que recibió la compañía.
Los titulares de derechos reportan aproximadamente 10 millones de nuevas URL por semana. Más de 1000 autores o editoriales reclaman la baja de diferentes enlaces. Con respecto a Spotify, los torrents con metadatos tomados de Spotify aún están disponibles. La música todavía no se publicó.

¿Por qué importan los metadatos? es grave principalmente por violaciones a términos de servicio, riesgos de privacidad y perjuicios económicos a la industria musical.
Y aquí pasan dos cosas. Por un lado, los dueños de los derechos de autor -que suelen ser las editoriales, discográficas y productoras de cine- lo consideran un robo, al igual que la justicia.
Por otro lado, los usuarios y comunidades que apoyan este a la cultura libre. Seguramente te bajaste alguna vez en tu vida una canción de Napster, de un Torrent, un canal de Telegram o un pirateaste un libro. No lo podías comprar y te pareció bien. Ni hablar de las series o películas en Stremio o Magis TV.
Si hacemos una encuesta y les pregunto “de que lado están”, ¿qué opinan?
Por otro lado, hay músicos que se están yendo de Spotify, pero no por esta razón, sino por invertir en una empresa de armas de inteligencia artificial. Primero lo hizo King Gizzard y luego Café Tacvba, que lo cuenta muy bien Fernando Sanchez en su último news. ¿Saben qué pasó con King Gizzard? Se llenó de imitaciones de la banda hechas con IA. Semanas atrás, si buscabas "King Gizzard" en Spotify, te aparecía el perfil oficial abandonado de la banda y abajo la recomendación de "King Lizard", una banda trucha que nos ofrece la versión plagiada del tema "Rattlesnake" hecho IA. Esta nota de Futurism explica del detalle.
¿Y con Café Tacvba? todavía no se retiró la música y Spotify contestó “Respetamos profundamente el legado artístico de Café Tacvba y el derecho de Rubén Albarrán a expresar libremente sus opiniones, pero los hechos cuentan una historia distinta. Spotify no financia la guerra”.
Más allá de las cuestiones éticas desmentidas por la empresa, el líder de Café Tacvba explicó otras razones: “publicidad de ICE (Servicio de Inmigración y Control de Aduanas de Estados Unidos), regalías de miseria y el uso de inteligencia artificial en detrimento de los músicos”. Y todo eso es cierto, hubo una campaña de reclutamiento que se publicitó en varios lugares, incluido Spotify, las regalías son ínfimas y la IA está complicando el panorama.
Para esta cobertura entrevisté a Tweety González, histórico músico y productor musical que además es fan de la tecnología y a Mauro Eldritch, experto en seguridad informática. Cada uno con una postura opuesta e interesante.
2) Tweety González: ¿que tan bien protegido tienen el contenido?
Le pregunté a Tweety González por qué estaba mal y cual era la importancia de los metadatos.

El catalogo completo con toda la metadata de absolutamente todas las canciones disponibles en Spotify disponible en el “Taringa mas famoso entre los universitarios del mundo”. Con todos los detalles, filtros, etc. que hasta hizo posible al sitio elaborar estadísticas del contenido. Todo disponible en formato Ogg Vorbis, que es un formato open source que libera de copyright y se usa para entrenar IA.
Ya sea porque acción (hicieron la vista gorda adrede o hay gente desleal en la compañía) u omisión (incluyendo inoperancia) a Spotify no se le puede colar esto en un sitio así. Por empezar ¿que tan bien protegido tienen el contenido? Se supone son los custodios e intermediarios entre las dos partes (usuarios y artistas). Es tremendo que este toda la librería y contenido expuestos, transformados y disponibles a cualquiera.
¿Cómo impacta el scraping masivo de Spotify al artista?
• Más chance de piratería/circulación fuera de Spotify.
• Riesgo de perfiles o subidas falsas (“clones”).
• Posible uso no autorizado para IA (voz/estilo).
• Algunas herramientas/analytics pueden fallar si Spotify endurece controles.
¿Y como sello (dueño del master)'?
• Menos control del activo: más costo de monitoreo y takedowns.
• Riesgo de “mirrors”/ republicaciones no autorizadas.
• Más fraude/ suplantación de catálogo por metadatos.
¿Como compositor/publisher?
• Riesgo mayor en IA y obras derivadas sin licencia.
• Posibles errores/manipulación de metadatos de autoría y splits.
• Más trabajo de reclamos/enforcement para cobrar lo que corresponde.
Efectivamente, luego de la filtración, el sitio de Anna's Archive publicó una serie de estadísticas con mucha información que no linkearé en este boletín, solo una imagen que ilustra el tipo de información. Por supuesto que es interesante de leer pero no era información pública. ¿la culpa la tienen los responsables de Anna's Archive o Spotify?
3) Mauro Eldritch: “mucho material logró conservarse así”
Le pregunté a Mauro Eldritch si esto es una filtración, un hackeo o cómo es la manera correcta de denominarlo y qué significa.
Las iniciativas de “conservación” digital no son algo nuevo, están dando vueltas desde hace muchos años y son transversales a distintas escenas.
Se daban mucho en el mundo de los videojuegos, con entusiastas haciendo ingeniería inversa de consolas y cartuchos/discos/cds/etc para poder conservar copias. Hoy en día los juegos de muchas de esas plataformas (algunas muertas hace más de 30 años) pueden jugarse en cualquier celular gracias a ese esfuerzo de conservación.
Estos movimientos recibieron muchas críticas e incluso demandas porque al fin del día pueden ser considerados piratería, pero también tienen otra cara: mucho material que podría considerarse hoy lost media (perdido) logró conservarse de esta manera e incluso los mismos fabricantes más de una vez se han beneficiado de estas “copias”. Tal es el caso de un gigante de ese mundo que volvió a publicar uno de sus juegos más viejos en Steam (una plataforma de juegos) hace poco, y algunos investigadores -haciendo ingeniería inversa- encontraron dentro del mismo una firma de un reconocido grupo pirata (el fabricante luego admitió que utilizaron la versión pirateada porque habían “perdido los originales por accidente”).
¿Y en el caso de la Spotify?
En el mundo de la música esto no es nuevo tampoco pero sí podría ser el índice más grande de música “respaldada” hasta el momento. Como decíamos, no hablamos de una filtración porque no la hubo, la persona o el colectivo que lo hizo simplemente utilizó una función propia de la aplicación, que permite descargar el material a un dispositivo (claramente luego entran otras cuestiones no permitidas como difundir ese material). Es similar a lo que te contaba arriba de la escena de los videojuegos, en foros no se hablaba de “Juegos piratas” sino de “backups de juegos”. “Yo tengo el cartucho, simplemente lo estoy volcando para tener una copia” era el argumento de ese momento (más allá de otras implicaciones legales).
Exactamente lo que dice Mauro, una cosa es un backup y otra es difundir ese material. La manera de hacerlo fue una mezcla de recursos. Por un lado, usaron muchas cuentas (legítimas, robadas o falsas) para hacer las peticiones de cada uno de los artistas. Por el otro, automatizaron este scraping a través de scripts y bots que solicitaban pistas continuamente a los servidores de Spotify. Descargaron los fragmentos de audio cifrados y los metadatos asociados de cada canción. Por último, reconstruyeron esos archivos, que fueron capturados en el cliente, los recombinaron en archivos OGG a 160 kbps y generaron copias reproducibles fuera de Spotify.
Spotify indicó que “utilizaron tácticas ilícitas para sortear la DRM y acceder a algunos de los archivos de audio de la plataforma”. Las cuentas ya fueron eliminadas.
¿Hay algún caso paradigmático al respecto?
Hace algunos (cuántos) años una buena parte del under argentino era muy activo en plataformas como SoundCloud y PureVolume. Con la caída de esta última, se perdió muchísimo material que hoy justamente es lost media, particularmente de artistas argentinos y de géneros que por ahí no son tan mainstream. Y esto es lamentable porque también es una pérdida para la cultura. Muchos de esos músicos o grupos no volvieron a subir su material y son imposibles de encontrar salvo por copias en YouTube o de aquellos que lo descargaron del sitio (probablemente contra la política de uso).
📧 ¿Cansados del correo lleno? Te recomiendo Meco como suite de correo para escapar del mail lleno y leer newsletters sin tanto ruido. ¡Es gratuita! Si te anotás, recibo una comisión como afiliado.

Empresas que apoyan a LadoBNews


Qué interesante para seguir indagando y debatiendo. Siempre en estos temas se entrecruzan derechos tan fundamentales como el acceso a la cultura (de forma irrestricta) y también la de los artistas que buscan vivir de su arte. Sin embargo, muchas veces presentados cómo opuestos cuando en muchas ocasiones eso ha logrado convivir. Sobre los metadados, me pregunto si los titulares de los derechos de las canciones son también dueños de los mismos. No me refiero al acceso a estadísticas (que Spotify ofrece), sino a poder llevarse esos metadatos si en algún momento deciden migrar a otro servicio. Creo que ahí también están las claves de muchos debates con los servicios de streaming (y que Jaron Lanier proponía, con una lógica intermedia, ni cultura libre ni tampoco la lógica de concentración de las plataformas actuales)
Los años pasan y el apasionante tironeo entre cultura y la industria editorial continúa (me siento como repasando viejas lecturas en derechoaleer.org). Entiendo todos los derechos que un autor tiene acerca de la protección de su obra y a poder vivir de ella. Pero claramente las plataformas no han podido... perdón, no han querido modificar el paradigma comercial de los sellos discográficos (entre otros). Así es como el copyright continua entonces protegiendo más al negocio que los pobres autores. Una vez más, todo cambió para no cambiar nada.
Ante lo inevitable, que el Tweety me perdone pero voto por el salvataje de la obra cultural de la manera más eficiente: su liberación y difusión al público.